Our group has a few papers at ACL 2026 in San Diego (2–7 July) and ICML 2026 in Seoul (6–11 July, at the COEX Convention & Exhibition Center), covering GUI agents, efficient generation, reasoning, robustness, and mechanistic interpretability. If you are attending either conference, come say hi! Here is where to find us and what we will be presenting.
ICML 2026 – GUI Agents & Efficient Generation
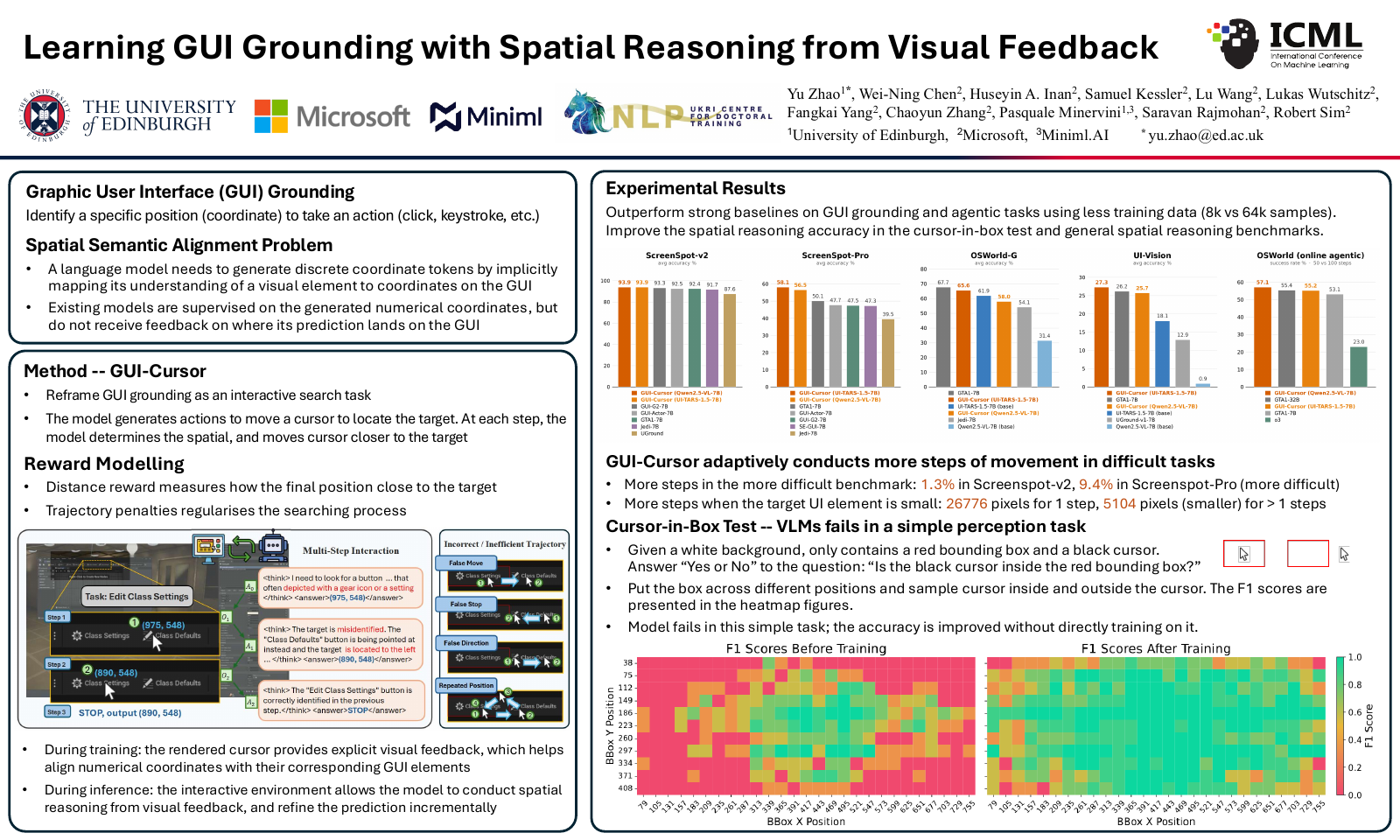
Learning GUI Grounding with Spatial Reasoning from Visual Feedback, led by Yu Zhao during his time at Microsoft Research Cambridge.
TLDR: Vision-Language Models often fail to predict accurate numeric coordinates when grounding instructions in high-resolution GUIs. GUI-Cursor reframes GUI grounding as an interactive search task: the model moves a visible cursor on the screen, and the rendered cursor provides visual feedback that helps align its predictions with on-screen locations. Trained with multi-step online reinforcement learning and a dense trajectory-based reward, GUI-Cursor achieves state-of-the-art accuracy on ScreenSpot-v2 (93.9%) and ScreenSpot-Pro (56.5%) while using far less training data than strong baselines (8k vs 64k samples), and learns to adaptively take more steps on more difficult examples.
Presented on Tuesday 7 July, 10:30am–12:15pm KST, Hall A, poster #2013 (ICML page).
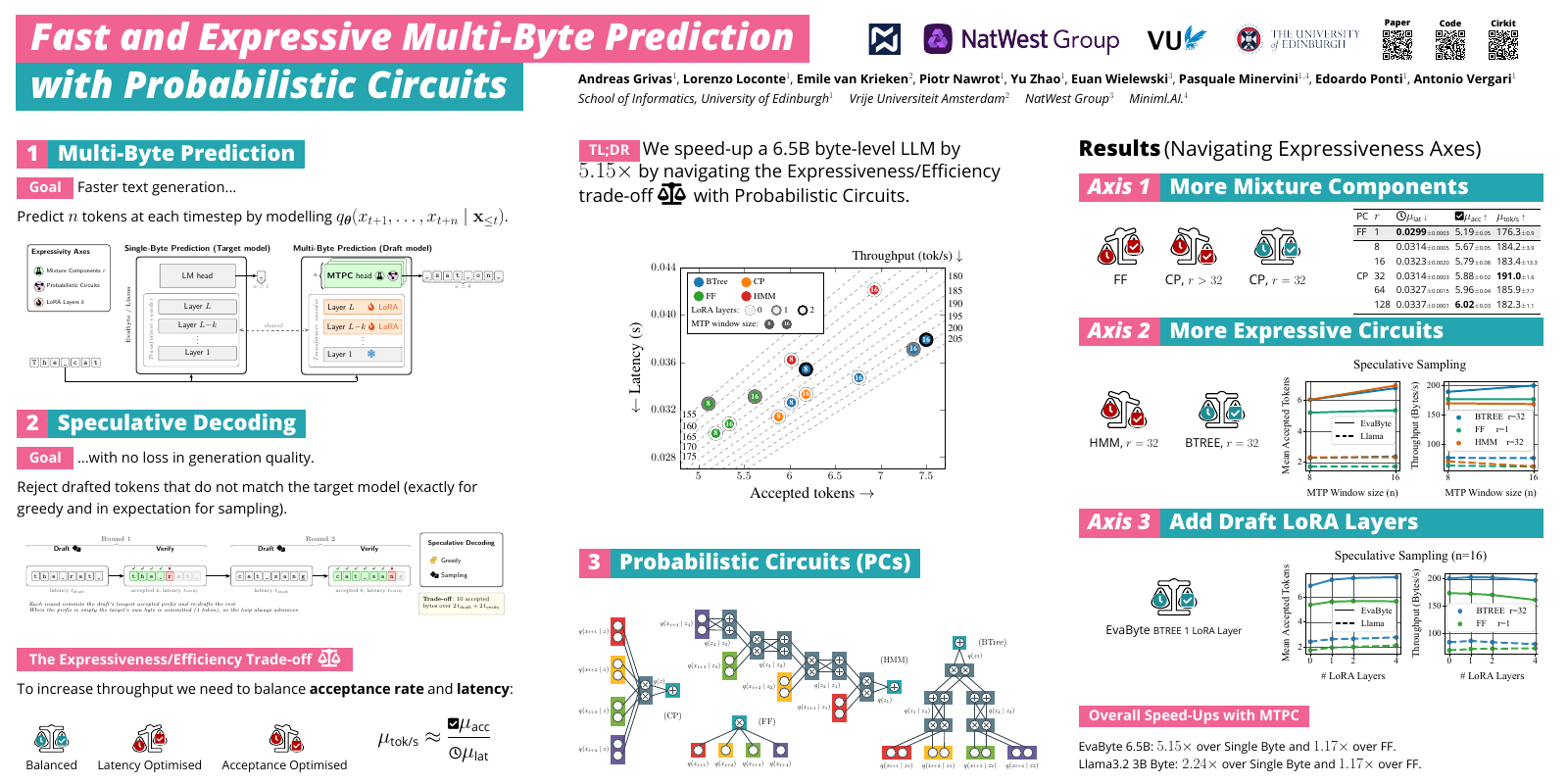
Fast and Expressive Multi-Byte Prediction with Probabilistic Circuits, led by Andreas Grivas during is postdoc with the amazing Edoardo and Antonio and their groups.
TLDR: Multi-token prediction speeds up generation in LLMs, but existing methods sacrifice expressiveness by assuming the future tokens are independent. Andreas’ MTPC models the joint distribution over future tokens with Probabilistic Circuits, generalising mixture models, HMMs, and tensor networks, and lets us navigate the expressiveness/latency trade-off along three axes: number of mixture components, circuit architecture, and draft LoRA layers. Combined with speculative decoding, MTPC speeds up the byte-level LLM EvaByte 6.5B by 5.15× and a byte-fied Llama 3.2 3B by 2.24×, with no loss in generation quality. Code here (and if you like PCs, make sure to check Antonio’s “April Tools” group’s GitHub as well!)
Presented on Tuesday 7 July, 10:30am–12:15pm KST, Hall A, poster #2607 (ICML page).
VLM-RobustBench: A Comprehensive Benchmark for Robustness of Vision-Language Models, led by the magic Rohit Saxena with Alessandro Suglia
VLMs perform impressively on clean images, but what happens when the input is distorted? VLM-RobustBench evaluates several VLM families (Qwen, InternVL, Molmo, Gemma) under 49 augmentation types – noise, blur, weather, digital, and geometric perturbations at multiple intensities, for 133 corrupted test conditions – on MMBench and MMMU-Pro. A key finding is that visual severity does not reliably predict degradation: mild glass blur costs ~8 accuracy points, while resampling and elastic transforms cause drops of up to 34 points, suggesting that current VLMs are semantically strong but spatially fragile. Check out the project page (ICML page).
Mech Interp Workshop @ ICML 2026 – Retrieval Heads
Logit-Contribution Scoring Identifies Non-Literal Retrieval Heads, led by Aryo Gema with her supervisor Bea
What makes an attention head a retrieval head? Existing detectors score where a head reads (the QK circuit), not what it writes (the OV circuit) – but for non-literal retrieval, a head may attend to “Eiffel Tower” while writing the “Yuki” direction. LOCOS scores the full QK-to-OV path, and ablating the top LOCOS heads degrades non-literal retrieval on NoLiMa more sharply than attention-based baselines across 6 models from 3 families, while leaving parametric recall and arithmetic largely intact. The selected heads also matter downstream, on MuSiQue and BABILong. More details on the project page!
Presented as a virtual poster at the Mechanistic Interpretability Workshop on Friday 10 July.

ACL 2026 – Reasoning
PiCSAR: Probabilistic Confidence Selection And Ranking for Reasoning Chains, led by Joshua Ong Jun Leang (now a PhD student with Eleonora Giunchiglia at Imperial)
PiCSAR is a training-free method for best-of-n reasoning: it scores each candidate generation using the joint log-likelihood of the reasoning chain and the final answer, decomposed into reasoning confidence and answer confidence. It yields substantial gains (+10.18 on MATH500, +9.81 on AIME2025), outperforming baselines with at least half as many samples in 16 out of 20 comparisons.
Presented at ACL 2026 in San Diego.
Other projects
SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks, led by Cyrus Kwan
Can LLMs self-improve on open-ended tasks without curated data? SCOPE co-evolves a Challenger that generates document-grounded tasks near the Solver’s frontier and a Solver that answers them through multi-turn retrieval, while a frozen Judge writes task-specific rubrics and grades the responses. Across three 7–8B models, SCOPE improves open-ended benchmarks by +5.4 to +10.4 points – matching or exceeding GRPO trained on ~9K curated prompts – and, although trained only on open-ended tasks, it improves held-out short-form QA by +7.8 to +13.8 points. Code and models here, and check out the project page!
Do Composed Image Retrieval Benchmarks Require Multimodal Composition?, led by Matteo Attimonelli during his visit to my group!
Composed Image Retrieval (CIR) asks a model to retrieve a target image given a reference image plus a textual modification – but does strong benchmark performance actually require composing the two modalities? Auditing four CIR benchmarks with eleven multimodal embedding models, we find that 32.2% to 83.6% of queries can be solved using a single modality, and human validation of the remaining shortcut-free queries shows that only 1,689 out of 4,741 are well-formed. Current benchmarks conflate shortcut-solvable, noisy, and genuinely compositional queries – and re-evaluating on the validated subset paints a rather different picture of the state of the art.